
Azure AKS スポットインスタンスを利用した Kubeflow パイプラインの運用
by jiashiuan on 2 March 2022
原典:https://ubuntu.com/blog/deploying-kubeflow-pipelines-with-azure-aks-spot-instances
はじめに
Charmed KubeflowはCanonicalが提供するMLOpsプラットフォームであり、AM/MLモデルの考案、トレーニング、リリース、メンテナンスなど、コンセプトから実運用まで対応するエンドツーエンドのソリューションを提供することにより、データエンジニアやデータサイエンティストの負担を軽減します。このために、Charmed KubeflowはKubeflowパイプラインを採用しています。これはフィーチャーエンジニアリング、ディープラーニングモデルのトレーニング、モデルアーティファクトの実験と実運用環境へのリリースなど、MLOpsのワークフロー全体の調整機能です。
このブログでは、Azureスポットインスタンスを利用し、Charmed KubeflowベースのMLOpsワークフローをMicrosoft Azureクラウドで実行するコストを最適化する方法について説明します。
スポットインスタンス
スポットインスタンスは、クラウドで仮想マシンを実行するコストを下げる1つの手段です。Azureなどのクラウドプロバイダーは空き容量を使用してスポットインスタンスを提供します。これがオンデマンドのインスタンスとまったく同じで価格が安いだけなら、誰でも利用するはずです。しかしクラウドプロバイダーは、この処理能力が必要になれば、ここで実行されているユーザーワークロードを排除することができます。このときスポットの構成に基づいて新しいインスタンスを提供しますが、ワークロードは中断されます。インスタンスのタイプに応じて、これが1%から20%の割合で発生します。
スポットインスタンスの価格は、特定のインスタンスタイプに利用できる空き容量によって変わります。同じインスタンスタイプを要求する人が多いときは、スポットインスタンスのコストが、その地域のオンデマンドインスタンスと同じになることもあります。そこでユーザーは支払う最高価格を指定できます。スポット価格がその値を超える場合、スポットインスタンスは排除されます。
MLOpsワークフロー
上述の特徴を考慮すれば、スポットインスタンスで実行するのに最適なワークロードは、時間の制約が厳しくなく、排除の影響を受けないものとなります。また、安定性よりコストを重視するなら、短いテストや高価なハードウェアを使用した実験にスポットインスタンスを使用することも可能です。
MLワークフローには、スポットインスタンスに適したものがいくつかあります。
- データ処理
- 分散トレーニングとハイパーパラメータチューニング
- モデルのトレーニング(長い時間を要するときはチェックポイントを入れます)
- バッチ推論
次のような用途にはスポットインスタンスを使うべきではありません。
- Kubernetesコントロールプレーン
- ノートブックとダッシュボード
- Minioやデータベースなどのデータストア
- オンライン推論に使用されるモデル
AKS – Azure Kubernetes Service
AKSはAzureのマネージドKubernetesサービスです。このサービスは、ノードプールと呼ばれるVMのグループに支持されています。ノードプールのすべてのインスタンスは同じタイプです。クラスターを作成するには、Kubernetesコントロールプレーンを実行するために、オンデマンドまたは予約インスタンスのプールが最低1つ必要です。スポットインスタンスは後から、ノードプールとして追加できます。
ノードプールの追加は、AKSクラスターでアプリケーションを正しく処理するための最初のステップ、手順にすぎません。スポットインスタンスにより支持されているノードには、taintというプロパティがあります。ポッドを特定のノードでスケジュールするには、toleranceプロパティが必要です。AKSのスポットインスタンスノードでポッドをスケジュールするには、taintの値に応じてポッドのtoleranceを構成する必要があります。
例
このような面倒な操作を行う価値がある理由について説明しましょう。20の異なるモデルについて、AKS上のCharmed KubeflowにMLOpsワークフローが実装されていると考えてみます。まず、単一のマシンタイプとして汎用マシンであるD4s_v3を使用しました。計算を簡単にするため、インスタンスのタイプは変更しないものとします。
毎月の想定は次のとおりです。
- モデルのトレーニングに400時間
- 実験の実行に1,000時間
- 20モデルのエンドポイントがオンライン推論に露出
- データ量は3TB
- ML用データの事前処理に2,000時間
まず、スポットインスタンスを使用できるワークフローを特定します。
- データ処理
- 実験の実行
- モデルのトレーニング
D4s_v3でのコンピューティングは合計3,400時間になります。この記事の執筆時点で、Azureのオンデマンドインスタンスの公開価格は時間あたり0.2320ドルです。1か月では約788ドルになります(英国南部地域)。
スポットインスタンスは、いつでも排除される可能性があります。Azureは、インスタンスタイプごとに推定排除率を公開しています。インスタンスタイプD4s_v3の排除率は5%です。つまりワークロードの5%に2倍の時間がかかります。合計処理時間は3,570時間に増えます。英国南部で現在公開されているスポットインスタンスの価格は1時間あたり0.0487ドル、1か月あたり約173ドルです(英国南部地域)。
2つの手法の価格は1か月あたり788ドルと173ドル、つまりデータ処理、実験の実行、モデルのトレーニングでスポットが78%割安になります。これなら、面倒でもセットアップする価値がありそうです。
実行中のシステムにスポットインスタンスを追加
既存のAKSクラスターをスポットインスタンスで拡張し、オーケストレーションエンジンでワークフローのステップをスケジュールしてみましょう。実装は次の3つの部分に分けました。
- 新しいノードプールのAKSクラスターへの追加
- ワークフロー定義の変更
- ワークフローの実行と結果の検証
準備
この実装を行うには、AKSに展開されている動作中のKubeflowが必要です。AKSクラスター上にKubeflowをセットアップする方法は、https://ubuntu.com/tutorials/install-kubeflow-on-azure-kubernetes-service-aksをご覧ください。使用しているKubeflowのバージョンは1.4です。

AKSクラスター

Kubeflowダッシュボード
新しいノードプール
クラスターの詳細画面で、[設定] -> [ノードプール] を選択します。JujuとCharmed Kubeflowのポッドをホストしているのは、単一のエージェントプールです。ここでは、スポットインスタンスを含めるため、ノードプールを追加します。その後でスポットインスタンスを設定し、アプリケーションが間違ってここに配置されないようにします。

[ノードプールの追加] を選択します。それから、[Azure Spotインスタンスを有効にする] を選択し、オンデマンドインスタンスでなくスポットインスタンスが使用されるようにします。

Azure Spotの構成は重要です。ここでは、いつ、どのようにノードの排除を許可するかを指定します(それぞれ [排除タイプ] と [排除ポリシー])。特定の価格以上でワークロードを実行する価値がない場合は、それを最高価格として指定します。

次に、ノードのVMサイズを選択します。Azureポータルには、現在の時間ごとのコストと、スポットインスタンスの割引率が示されています。これらの価格は動的に変化することに注意してください。また、ここで示されている排除率は保証されているものではありません。これらのパラメータはすべて、VMのサイズを選択し、スポットインスタンス使用のTCO(総所有コスト)を計算するため重要なものです。

すべての必須フィールドに入力したら、プールの作成に進みます。VMが開始するには多少の時間が必要です。Azureポータルの [ノードプール] タブ、またはkubectlを使用して、すべてのノードが利用可能かどうかをチェックできます。

スポットインスタンスプールを追加した後のノードプールのリスト
kubectl get nodes

オンデマンドインスタンスでのワークフロー
Kubeflowノートブックに新しいノートブックを作成し、リポジトリをhttps://github.com/Barteus/kubeflow-examplesから複製します。このブログ投稿のノートブックはaks-spot-instanceフォルダにあります。同じ操作を行っても、フォルダからノートブックを実行してもかまいません。手順がわかりやすいよう番号を付けてあります。

複製したリポジトリを含むJupyterノートブック
初回の実行では何も変更せず、01-base-workloadノートブックを開いて実行します。デフォルトのKubeflowパイプラインの動作を確認しましょう。ワークフローの実行の詳細を確認するには、Kubeflowダッシュボードで [実行の詳細] リンクをクリックすると、KubeflowパイプラインUIが表示されます。

実行されたノートブックセルによる基本ワークフローの定義
ワークフローは正しく実行されました。TGZファイルをダウンロードして展開し、パッケージ内のすべてのCSVファイルを連結しました。期待どおり中間結果はすべてMinioに保存されています。また、ポッドのログと実行の一般的な状態はKubeflowパイプラインUIでチェックできます。スケジューラがスポットインスタンスのプールノードにタスクを配置していないことを確認します。1つの方法は、ポッドの長い定義YAML([nodeName] というフィールドの下)を見ることです。
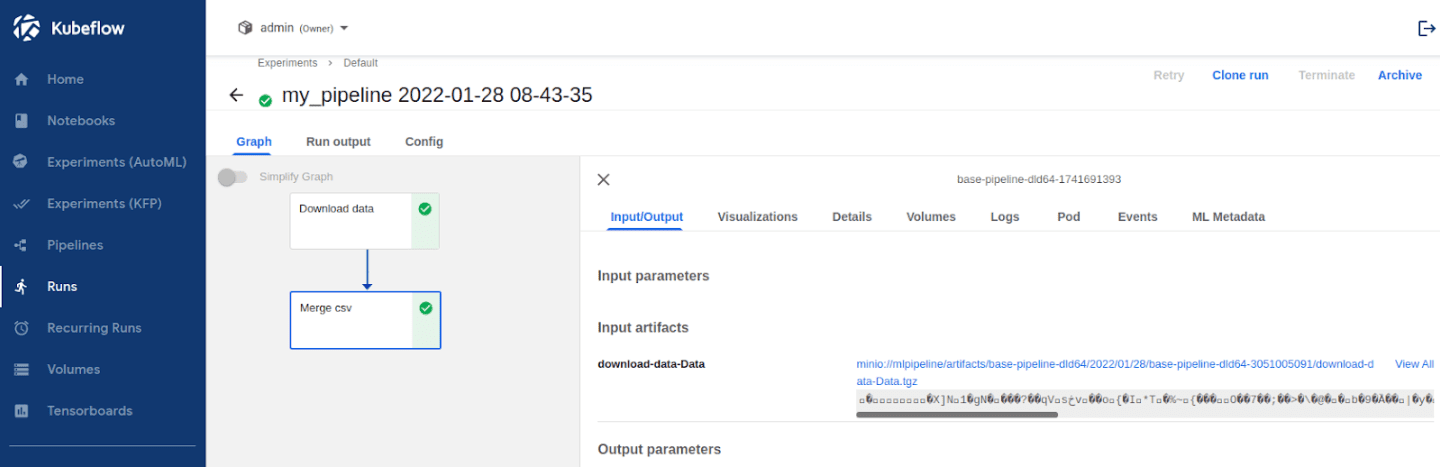
Kubeflowダッシュボードで実行される基本ワークフロー
もう1つは、kubectlを使用することです。
kubectl get pods -n admin -o wide
[ノード] 列で、すべてのタスクはエージェントプールで実行されたことを確認できます。タスクがスポットインスタンスプールで実行することを許可していないので、これは当然の結果です。

スポットインスタンスのワークフロー
次に、スポットインスタンスでタスクの実行を許可します。このためには、Kubernetes Toleration機構が役立ちます。各タスクに適切なTolerationを追加することで、スポットインスタンスで実行可能になります。他の部分はスケジュールに任せることができ、ほとんどの場合はすべてのタスクがスポットインスタンスで実行されますが、確実ではありません。特定のタイプのノードで実行する必要があるタスクが存在するなら(必要なGPUのサイズなど)、アフィニティ構成を追加し、タスクの実行に使用可能なポッドのタイプを限定する必要があります。
この変更はパイプラインレベルでのみ行います。タスクは適用されるKubernetes構成の詳細を認識しません。前のmy_pipelineメソッドのTolerationとAffinityを変更しました。タスクごとに構成がセットアップされます。これにより、タスクを多少柔軟に、最もコスト効率の高いノードで実行できます。

実行されたノートブックセルによる、スポットインスタンスベースのワークフローの定義
変更後のパイプラインは正常に動作し、同じ作業を行います。変更はポッドの定義にある [nodeName] で見ることができます。

Kubeflowダッシュボードで実行されるスポットインスタンスベースのワークフロー
「spot-pipeline」がどのノードで実行されたのかをチェックしましょう。
kubectl get pods -n admin -o wide | grep “spot-pipeline”

AffinityとToleranceが期待したように作用し、両方のタスクはスポットインスタンスで実行されました。
猶予付きの排除処理
スポットインスタンスを使用して、Kubeflowパイプラインで効率的にデータを処理する、実際に動作するソリューションができあがりました。スポットインスタンスについて、もう1つ覚えておく必要があるのは排除です。ノードVMはどの時点でも排除される可能性がありますが、これに猶予を持たせる必要があります。ここでは、Kubeflowパイプラインのリトライ機能が役立ちます。スポットインスタンスで実行される各タスクについて、リトライポリシーを設定できます。スポットインスタンスが終了され、タスクが失敗したとき、Kubeflowパイプラインはしばらく待ってからタスクをリトライします。これは、最大リトライ回数に達するまで繰り返されます。
タスクのリトライは最大5回、リトライの間隔は5分に設定し、新しいノードがスポーンする時間を作ります。

実行されたノートブックセル:スポットインスタンスベースのリトライ付きワークフローを定義
ここでも、ワークフローは完全に正しく実行されます。タスクの実行中にスポットインスタンスが排除されると、5分後にリトライが行われます。

リトライのあるスポットインスタンスベースのワークフローをKubeflowダッシュボードで実行
Kubeflowパイプラインの定義にリトライを追加したことで、実行中の「ランダムな」エラーも解決できます。排除率が20%を超えるインスタンスタイプでは、このようなエラーの回数が増えることに注目してください。
まとめ
この記事では、AKSクラスターに新しいスポットインスタンスプールを追加し、Kubeflowパイプラインワークフローがスポットインスタンスを使用して排除を適切に処理する手順を説明しました。
以下の点に注意が必要です。
- スポットインスタンスは、時間の制約が厳しくないワークフローをMLOpsワークフロー内で実行する経済的な方法です。
- スポットインスタンスはどの時点でも追い出される可能性があるため、ワークフローではこれに猶予を持たせる必要があります。
- Jupyterノートブックおよびデータストアは、スポットインスタンスに配置すべきではありません。
- モデルのトレーニング、データの事前処理、およびバッチ推論は、スポットインスタンスに適しています。
参考リンク
使用したデモ用ワークフローのベース:https://www.kubeflow.org/docs/components/pipelines/sdk/build-pipeline/
ニュースレターのサインアップ
関連記事
Canonical、Azure IoT運用を革新
Canonical、Microsoft Azure IoT Operationsに最適なプラットフォームを提供 CanonicalはMicrosoftの早期導入パートナーとして、Ubuntu CoreとKubernetes上でMicrosoft Azure IoT Operationsのテストを行ってきました。この協力が実を結び、本日Microsoftは、ノードデータのキャプチャ、エッジベースのテレメトリ処理、クラウドイングレスを大幅に改良した統合データプレーン、Azure IoT Operationsをリリースしました。Azure IoT OperationsはAzureのアダプティブクラウドに必須の要素であり、ハイブリッド、マルチクラウド、エッジ、IoTの環境を統合し […]
コネクテッドカー向けのソフトウェア開発:Anbox Cloudで着実に前進
大手自動車メーカーの間で、車載インフォテイメント用のオペレーティングシステムとしてAndroid Automotive OS(AAOS)が人気です。AAOSは、車内でもAndroidスマホと同様にさまざまなアプリケーション、機能、サービスを使用するための総合的なインフォテイメントプラットフォームです。 AAOSを使えば運転を楽しく快適にする新しいアプリケーションや機能の開発が容易になるため、対応アプリやサービスのエコシステムが急速に成長しています。 しかし、安定したインフォテイメントシステムの開発は、困難に満ちた長い道のりです。ハードウェアの提供状況、ロジスティクス、システム設定にも多くの課題があります。たとえばハードウェアの依存関係が問題を引き起こし、テストを遅らせるこ […]
アプリケーションセキュリティ(AppSec)とは?
サイバーセキュリティの世界は変わりました。サイバー攻撃、マルウェア、ランサムウェアのリスク増大に加え、新しいサイバーセキュリティ規制の圧力、情報漏洩や違反にかかる高額の罰金により、もはやアプリケーションセキュリティ(AppSec)は必須です。 このブログ記事では、このような課題に対処し、基本的なセキュリティ対策を中心として業務やシステムを守る方法を紹介します。AppSecの概要と利点、AppSecの設計と実装に取り組む方法を説明した後、セキュリティに関するCanonicalチームのアドバイスとAppSecのベストプラクティスを検討しましょう。 AppSecとは アプリケーションセキュリティ(略してAppSec)とは、アプリケーションのライフサイクルを通じて脆弱性の悪用を防 […]